Team Members: Umair Z. Ahmed, Shubham Sahai, Ben Leong
Collaborator: Amey Karkare (IIT Kanpur)
About This Project
There is a growing temptation to simply replace human Teaching Assistants (TA) with LLM-based chatbots. We wanted to test a different idea: what if we used AI to augment human TAs instead of replacing them?
programming students. Depending on their group, feedback is routed through AI, TA, or hybrid (TA + AI)
We ran one of the first large-scale randomised trials of this kind with 185 CS1 undergraduates at IIT Kanpur during a live, graded programming lab. Students worked on C programming exercises involving pointers and linked lists, where misconceptions are common and feedback quality really matters. We built an automated assistant powered by GPT-4 Turbo that could generate line-level feedback for buggy student code, and integrated it into the students’ existing programming environment (Prutor) so they would not notice any change in their workflow.
Students were split into six experimental groups. Some received feedback directly from the AI (in either a default or Socratic style). Others received feedback from human TAs who had access to AI-drafted hints they could review, edit, or ignore. A third set worked with TAs who had no AI assistance at all.
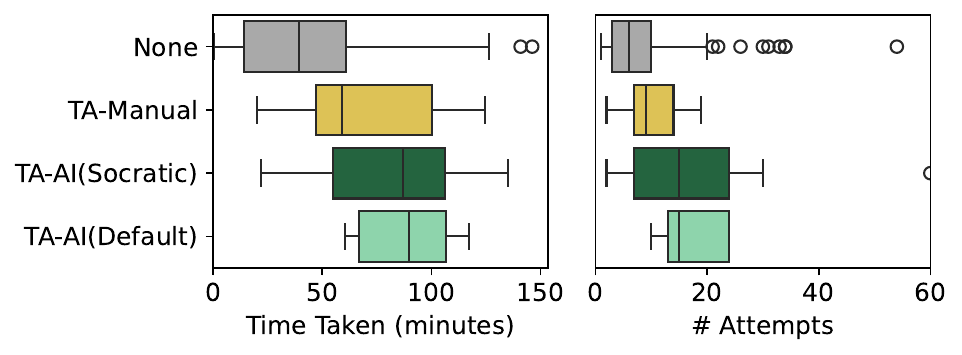
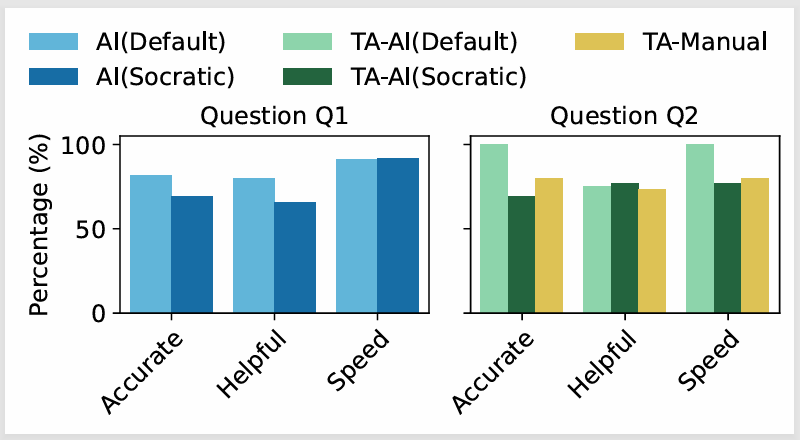
The results were surprising. Students perceived the AI-augmented feedback as more accurate and helpful, but when we looked at actual performance, students who were helped by unassisted TAs completed the harder question faster and in fewer attempts. It turns out human TAs without AI tended to give shorter, more direct feedback (averaging 13 words vs. the AI’s 129), sometimes just pointing students at the immediate next step. This brevity, while less “impressive” to students, was more effective at getting them unstuck.
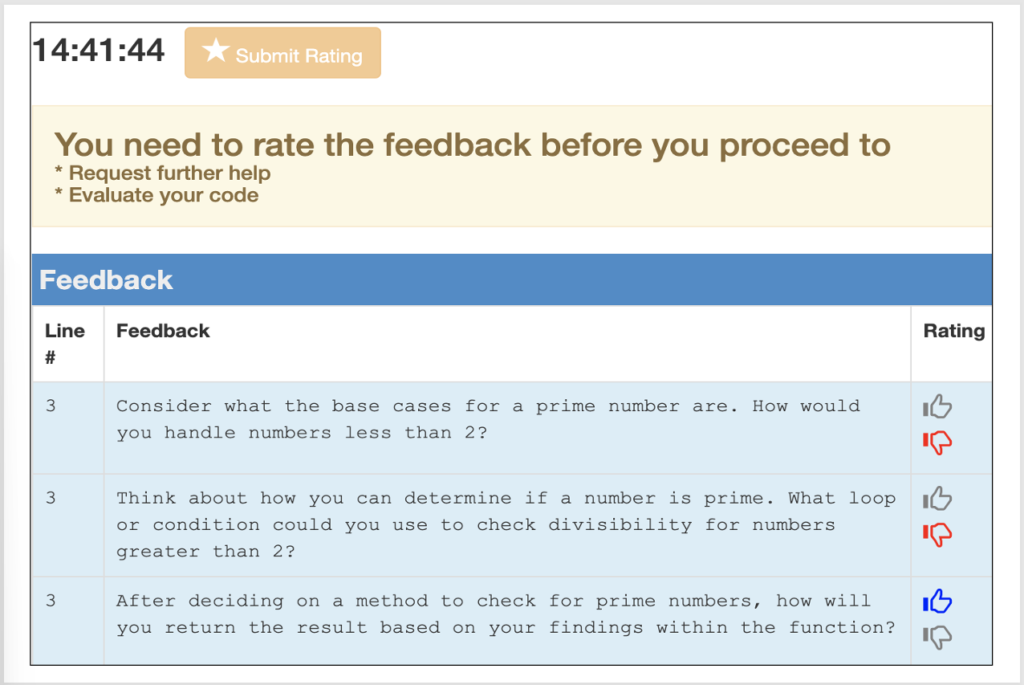
More concerning was a pattern of TA complacency. In 83% of cases, TAs added their own comments on top of the AI output, but not a single TA ever deleted AI-generated content, even though roughly 9% of it contained hallucinations as per expert evaluation.
Only one TA across the entire experiment edited the AI text before sending it. The human-in-the-loop, in practice, was not catching the errors we expected them to filter out.
We also found that students could not reliably identify hallucinated feedback, and rated it just as positively as correct feedback. Expert reviewers, by contrast, spotted these issues easily and rated them lower.
This gap between student satisfaction and actual feedback quality is a real risk for any institution considering AI-generated feedback at scale.
Research Questions
Methods
Randomised
Controlled Trial
User Study
(185 Students, Live Graded Lab)
Qualitative Feedback
Analysis
Large Language Models
(GPT-4 Turbo)
Key Contributions
- Students helped by unassisted TAs outperformed those receiving AI-augmented feedback on the harder question. Human TAs without AI gave shorter, more focused feedback (avg. 13 words vs. AI’s 129 words) that got students unstuck faster, sometimes by just pointing at the immediate next step.
- AI feedback style had no significant effect on outcomes: students receiving default-style and Socratic-style AI feedback had comparable completion rates (p = 0.85), though students preferred the more direct style.
- TA complacency was pervasive. In 83% of responses, TAs added comments on top of AI output—but no TA ever deleted AI-generated content, and only one TA edited it, despite a 9% hallucination rate in the AI feedback.
- Students cannot reliably detect hallucinations: they rated hallucinated feedback just as positively as correct feedback. Expert reviewers easily identified these issues, revealing a dangerous gap between student satisfaction and actual feedback quality.
- Socratic-style AI feedback imposed a cognitive burden on TAs, causing them to take significantly longer to respond (p = 0.03) than TAs working without any AI support.
- Our AI agent achieved a precision of 87% with a hallucination rate of 8.7%, which was surprisingly comparable to human TAs who achieved 88% precision, including one instance of a human TA hallucinating on the student’s request!
Publications
[1] Umair Z. Ahmed, Shubham Sahai, Ben Leong and Amey Karkare, ‘Feasibility Study of Augmenting Teaching Assistants with AI for CS1 Teaching’. Technical Symposium on Computer Science Education (SIGCSE TS 2025). Pittsburgh, USA. Feb 2025.
[2] Shubham Sahai, Umair Ahmed, and Ben Leong. ‘Improving the Coverage of GPT for Automated Feedback on High School Programming Assignments’. Proceedings of the NeurIPS’23 Workshop on Generative AI for Education (GAIED). New Orleans, USA. Dec 2023.
[3] Yang Hu, Umair Z. Ahmed, Sergey Mechtaev, Ben Leong, and Abhik Roychoudhury. ‘Re-factoring based Program Repair applied to Programming Assignments’. 34th IEEE/ACM International Conference on Automated Software Engineering (ASE). San Diego, USA. Nov 2019.
Additional Resources & Figures
Datasets
SIGCSE 2025 User Study Artifacts: Experimental data from the 185-student randomised trial: anonymised data, feedback logs, student ratings, expert annotations, and performance metrics.
Code & Tools
SIGCSE 2025 User Study Artifacts: Analysis scripts for the randomised controlled trial.