Team Members: Umair Z. Ahmed, Shubham Sahai, Ben Leong
Collaborator: Suryaansh Jain (Summer Intern 2025)
About This Project
Every few weeks a new Large Language Model drops, and developers face the same question: should we switch? Human evaluation is the gold standard, but it does not scale. The popular alternative of using one LLM to judge another (“LLM-As-A-Judge”) turns out to have a serious blind spot.
We ran a large-scale empirical study using 14 state-of-the-art LLMs, each evaluating feedback generated by all 14 models on 366 buggy high-school Python programs. The results were striking: LLMs are very good at recognising correct outputs (True Positive Rate or TPR, above 96%), but remarkably bad at catching incorrect or hallucinated ones (True Negative Rate or TNR, below 25%). In other words, they were over-agreeable in almost always agreeing that output looks fine, even when it is wrong.
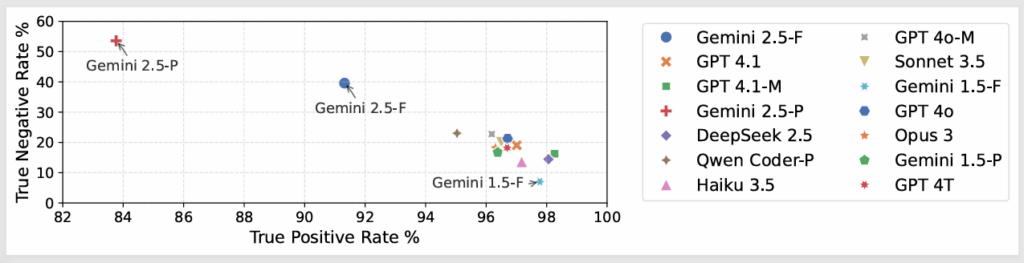
This matters because in most real datasets the fraction of invalid outputs is small, so the high overall “accuracy” masks the fact that the judge is essentially rubber-stamping everything. We showed that standard majority voting across an ensemble of judges helps only marginally. Instead, we proposed a minority-veto strategy: if even a small number of judges flag an output, treat it as suspect – which proved far more robust, even when validator data was noisy or incomplete.
For cases demanding even higher precision, we developed a regression-based framework that explicitly models each validator’s bias (its TPR and TNR) using just a handful of human-annotated datasets for calibration. With only five such datasets, this approach brought our maximum absolute error down to 1.2% – a 2× improvement over the best 14-model ensemble. The entire pipeline, dataset, and code are publicly available.
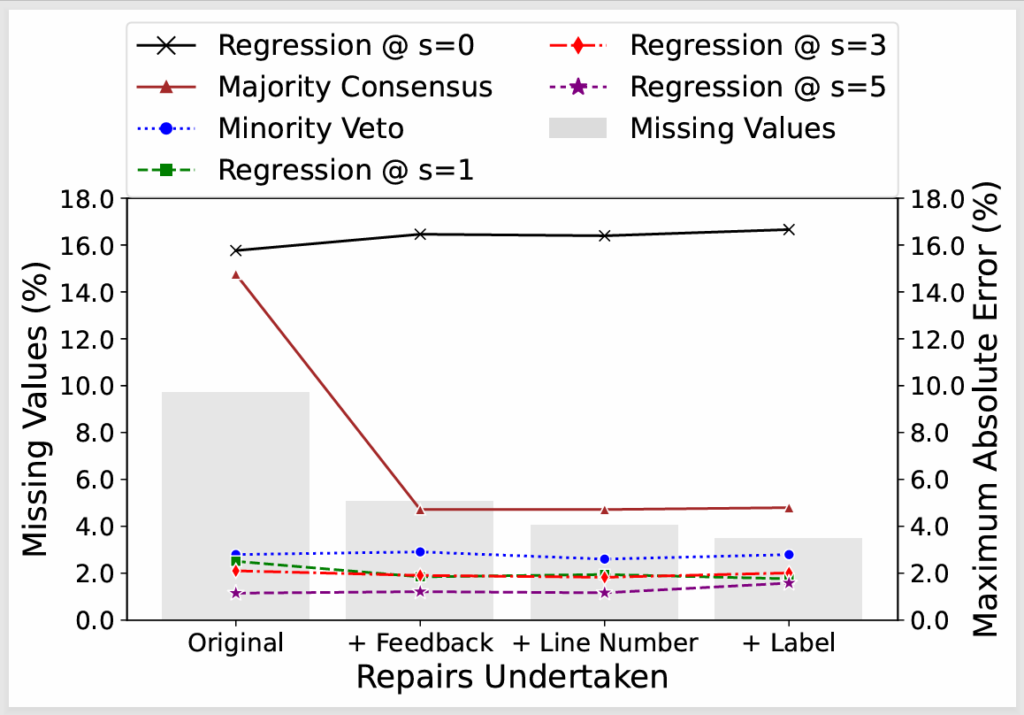
model is given more calibration data, outperforming all ensemble methods even at s=1
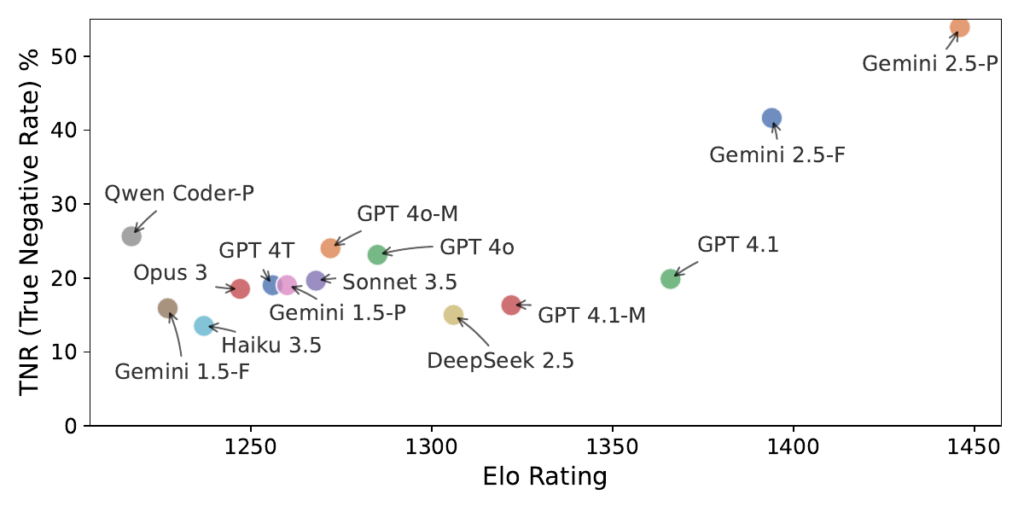
High Elo does not predict good validation capability
Research Questions
Methods
LLM-As-A-Judge
Evaluation
Ensemble Methods
(Majority Vote, Minority Veto)
Regression-Based
Bias Correction
Empirical Benchmarking
(14 LLMs)
Key Contributions
- LLMs are over aggreable: across all 14 models tested, validators correctly identified valid feedback over 96% of the time but caught invalid or hallucinated feedback less than 25% of the time. This agreeableness bias makes them unreliable for automated evaluation.
- High Elo rankings do not predict good judgement. Even flagship models like Gemini 2.5-Pro, which excel as generators, struggled as validators – its best TNR of 53.5% came at the cost of the lowest TPR at 83.8% among all models.
- Standard majority voting reduces the worst-case error from 17.6% to 14.8%, but the method isn’t robust: roughly 9.7% of validator outputs were malformed or missing, and majority voting is highly sensitive to these failures.
- Our minority-veto strategy, flagging an output as invalid if at least 4 of 14 judges say so, cut the maximum error to 2.8% and proved robust to missing data, unlike majority consensus.
- The regression-based bias correction framework, calibrated on just five human-annotated generator datasets (~200 person-hours of annotation), reduced the maximum absolute error to 1.2% – a 2× improvement over the best ensemble and resilient to noisy or incomplete validation data.
Publications
[1] Umair Z. Ahmed, Shubham Sahai, Suryaansh Jain and Ben Leong, ‘Beyond Consensus: Mitigating the Agreeableness Bias in LLM Judge Evaluations’. arXiv preprint arXiv:2510.11822, Oct 2025.
Additional Resources & Figures
Datasets
LLM Judge Calibration Dataset: 366 buggy Python programs, feedback from 14 LLMs, validation judgments from all 14 models, and human annotations for 6 generators.
Code & Tools
llm-judge-calibration: Full code and data for the regression-based bias correction framework and minority-veto strategy.