Addressing the growing challenge in evaluating LLMs at scale by mitigating the strong positive bias in LLM-as-a-judge approaches.
Lead PI:
Team Members:
Research Period:
Prof. Ben Leong Wing Lup
Suryaansh Jain, Umair Z. Ahmed, Shubham Sahai
2024 – 2025
About This Project
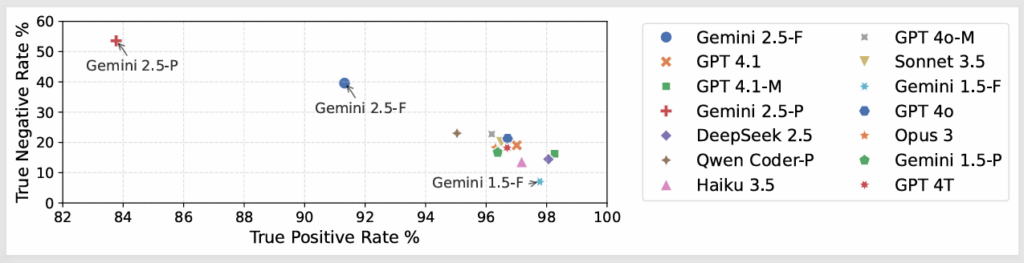
We conducted a research study on the reliable evaluation of LLM-generated outputs, addressing the growing challenge in evaluating LLMs at scale. Our analysis shows that while LLM-as-a-judge approaches achieve high accuracy in identifying valid outputs (True Positive Rate >96%), they exhibit a strong positive bias and perform poorly at detecting invalid outputs (True Negative Rate <25%), leading to inflated precision estimates. We showed that standard ensemble method of majority voting is insufficient and proposed a novel minority-veto strategy that mitigates this bias and is robust to missing data. We also developed a regression-based evaluation framework that models evaluation bias using a small amount of human-annotated data, to further improve results.
Agreeableness bias in LLM validators showing high True Positive Rate but low True Negative Rate
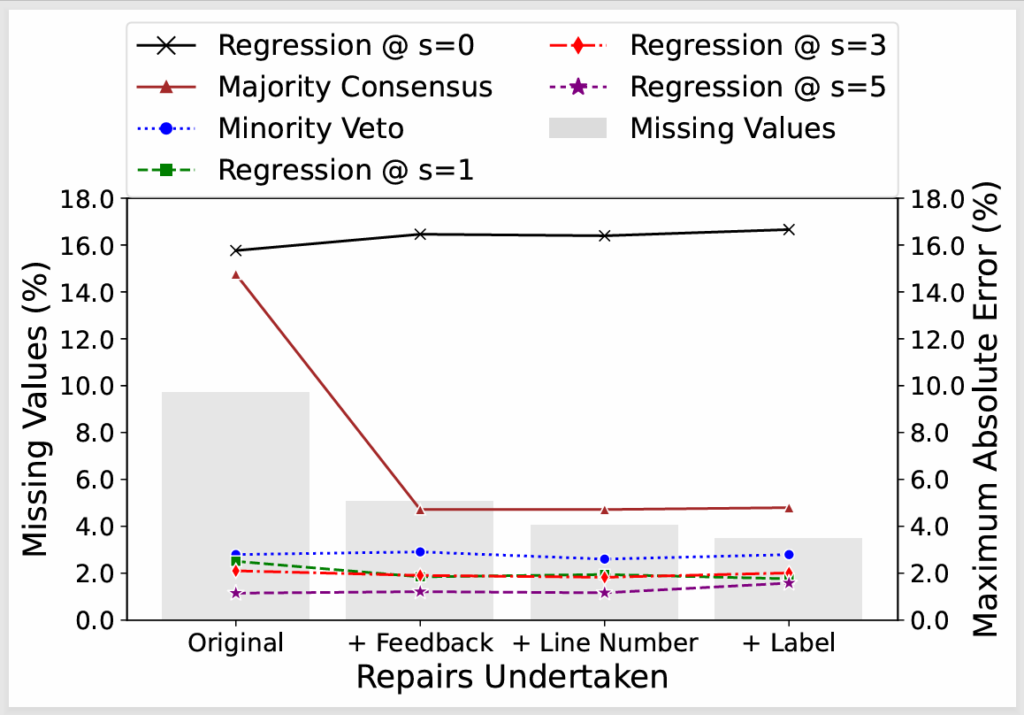
Mean of the Maximum Absolute Error (MAE) for different approaches across data repair strategies
Publications: Beyond consensus: Mitigating the agreeableness bias in llm judge evaluations
Leave a Reply